What’s Partitioning
Split the big table into multiple logical tables in the same table.
When to use Partitioning?
If table size is bigger and bigger , Indexes should being large, the queries could slower than before
Partition the table with index!
=> Query to small size indexes so targeting specific partitioned table!
=> Faster than whole index scanning!
Horizontal vs Vertical Partitioning
Horizontal
Split rows range, list, hash based.
Vertical
Splits columns partitions (Not recommended)
Partitioning Types
Range
Dates, ids
(e.g. year of logDateTime , userId)
ex) If you don’t use log date before 2015 years, You can archive old partitions to cheap storages.
List
Discrete values
ex) zip codes
Hash
Hash function decides where to store the data.
Cassandra, DynamoDB uses this strategy as default.
⚠️Partitioning is not Sharding
Sharding splits big table into multiple physical tables across multiple DB Servers. On the other hand, Partitioning have multiple logical tables in same table in same server.
Example partitioning in postgres
Normal table
1. Create test table
1
2
3
4
5
6
7
CREATE TABLE grades
(
id integer generated always as identity
constraint grades_pk
primary key,
grade integer not null
);
2. Insert 10 million rows.
1
2
3
4
5
INSERT INTO grades(grade)
-- key range (0 ~ 99)
SELECT floor(random() * 100)
-- generate 10 million rows
FROM generate_series (0, 10000000);
3. Create index on grade
1
2
3
4
5
6
CREATE INDEX grades_grade_index ON grades(grade);
SELECT COUNT(*)
FROM grades
WHERE grade = 30;
-- 100103
4. query on table
Non partitioning result (equal query)
1
2
3
4
-- Let's analyze query execution plan
EXPLAIN ANALYZE SELECT COUNT(*)
FROM grades
WHERE grade = 30;
1
2
3
4
-- on base table's index!
Index Only Scan using grades_grade_index on grades
Heap Fetches: 0
Execution Time: 20.612 ms
Non partitioning result (range-based query)
1
2
3
EXPLAIN ANALYZE SELECT COUNT(*)
FROM grades
WHERE grade BETWEEN 30 AND 35;
1
2
3
Parallel Index Only Scan using ...
Heap Fetches: 0
Execution Time: 42.094 ms
💡 You must execute above first, and follow next section since it’s reused in this section above the
gradestable.
Partitioning Table
1. create table with partition
1
2
3
4
5
6
create table grades_partition
(
id integer generated by default as identity,
grade integer not null
)
partition by RANGE (grade)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
CREATE TABLE g0025 (LIKE grades_partition INCLUDING INDEXES);
ALTER TABLE grades_partition
ATTACH PARTITION g0025
FOR VALUES FROM (0) to (25);
CREATE TABLE g2550 (LIKE grades_partition INCLUDING INDEXES);
ALTER TABLE grades_partition
ATTACH PARTITION g2550
FOR VALUES FROM (25) to (50);
CREATE TABLE g5075 (LIKE grades_partition INCLUDING INDEXES);
ALTER TABLE grades_partition
ATTACH PARTITION g5075
FOR VALUES FROM (50) to (75);
CREATE TABLE g75100 (LIKE grades_partition INCLUDING INDEXES);
ALTER TABLE grades_partition
ATTACH PARTITION g75100
FOR VALUES FROM (75) to (100);

2. Insert 10 million rows from grades table
1
2
3
INSERT INTO grades_partition
SELECT *
FROM grades;
Everytime you insert row to grade_partition table,
The DB will decide which partitoin that row goes to based on the value of grade.
1
2
3
4
SELECT COUNT(*)
FROM g0025;
-- count: 2499474
-- only partitioned rows are showned!
3. Create Index
Only create index on leader partition table
It will crate same index on all the partitions!
1
CREATE INDEX grades_partition_idx ON grades_partition(grade);
4. Query on table
1
2
3
EXPLAIN ANALYZE SELECT COUNT(*)
FROM grades_partition
WHERE grade = 30; -- 30 on partition 'g2550'
Partitioned result
1
2
3
-- search index in partition 'g2550'
Index Only Scan using g2550_grade_idx on g2550 grades_partition
Execution Time: 17.511 ms
Even if not shown difference between non-partition since my M1 Macbook Pro have enough RAM memory and performance.
There should be difference between them if there’s limit of main memory or lower performance environment.
Large index size (Non - partitioned table) vs Small index size (Partitioned table)
Compare the size
1
2
3
4
-- give you the size of the relation
SELECT pg_relation_size(oid), relname
FROM pg_class
ORDER BY pg_relation_size(oid) DESC;
Non-partitioned table
Large data and index size 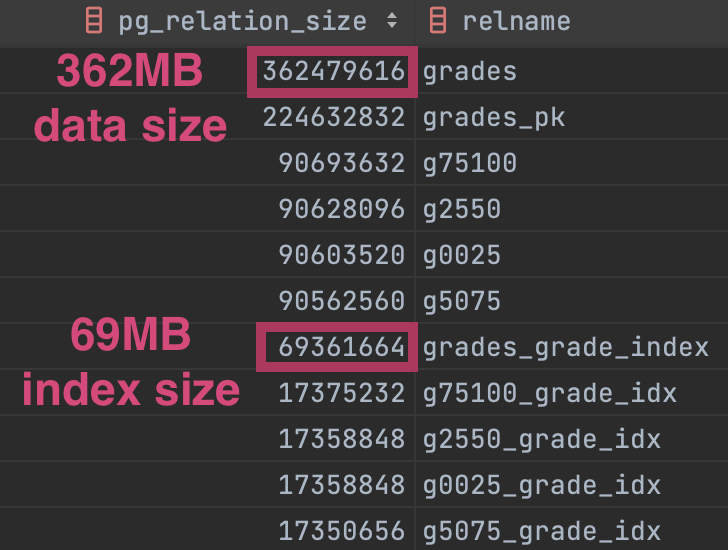
Partitioned table
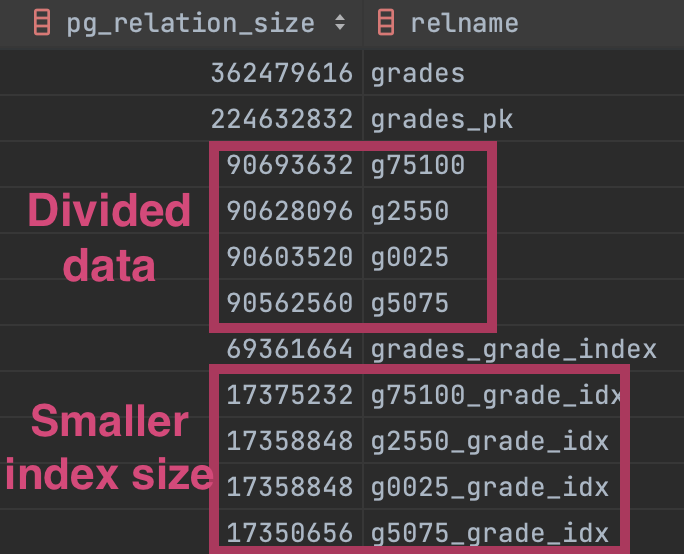
Smaller indexes size guarantee better performance on index scan query!
📝 Tips
Always enable
partition prunning!
1
SET enable_partition_pruning = on; -- default on
If you off that option, query will scan all partitions across whole table.
Pros and Cons of Partitioning
Pros
- Improves query performance
Lower size data (index size also) -> Fast query performance - Easy bulk loading
You don’t need caring about to which partition the data belongs.
DB automatically decides it. - Archive old data efficiently
If you barely query on specific partition table (ex. old data), you could archive it into cheap storage.
Cons
Slow update
When you move entire rows from one partition to another, it should delete rows and inserting ones.
It’s so slower than just updating rows.Inefficient when scan all partitions.
Suppose you scan all data in table partitioned.
It’s slower than a single table since it should jump from one partition to another one.Schema changes could be challenging
If master table has index, child tables also do it. However, it would not be always done.
The tables actually has to support this feature.